今天,我们兴奋地宣布推出 AI Labyrinth,这是一种全新的防御方法,它利用人工智能生成的内容来减缓、迷惑并消耗 AI 爬虫和其他不遵守“禁止抓取”指令的机器人的资源。当您选择加入后,Cloudflare 会在我们检测到不当的机器人活动时自动部署一组由 AI 生成的链接页面,而无需客户创建任何自定义规则。
所有客户,包括免费计划用户,均可选择加入 AI Labyrinth。
将生成式 AI 用作防御武器
据报道,去年秋天,人工智能生成的内容激增,占据了 Facebook 前 20 名帖子中的 4 个。此外,Medium 估计其平台上 47% 的内容 是由 AI 生成的。与任何新兴工具一样,它既有精彩的用途,也有恶意的用途。
与此同时,我们也看到 AI 公司用于抓取数据以进行模型训练的新爬虫数量激增。AI 爬虫每天向 Cloudflare 网络生成超过 500 亿个请求,约占我们所见所有 Web 请求的 1%。虽然 Cloudflare 有多种工具可用于识别和阻止未经授权的 AI 抓取,但我们发现阻止恶意机器人会提醒攻击者您已察觉到他们,从而导致攻击方式的转变,以及一场永无止境的军备竞赛。因此,我们希望创造一种新的方法来阻止这些不受欢迎的机器人,同时不让它们知道自己已被阻止。
为此,我们决定使用机器人创建者工具集中一种我们尚未真正用于防御的新型攻击工具:AI 生成的内容。当我们检测到未经授权的抓取时,我们不会阻止请求,而是会链接到一系列 AI 生成的页面,这些页面足以诱使爬虫遍历它们。但是,虽然看起来很真实,但这些内容实际上并不是我们正在保护的站点的内容,因此爬虫会浪费时间和资源。
此外,AI Labyrinth 还充当了下一代蜜罐。没有真正的人类会深入到由 AI 生成的无意义内容迷宫中四个链接的深度。任何这样做的访问者都极有可能是机器人,因此这为我们提供了一种全新的工具来识别和标记不良机器人,我们会将其添加到已知的不良行为者列表中。以下是我们如何做到的……
我们如何构建迷宫
当 AI 爬虫跟踪这些链接时,它们会浪费宝贵的计算资源来处理不相关的内容,而不是提取您合法的网站数据。这大大降低了它们收集足够有用信息以有效训练其模型的能力。
为了生成令人信服的类人内容,我们使用了 Workers AI 和一个开源模型来创建关于不同主题的独特 HTML 页面。我们没有按需创建这些内容(这可能会影响性能),而是实现了一个预生成管道,该管道会对内容进行清理以防止任何 XSS 漏洞,并将其存储在 R2 中以便更快地检索。我们发现,首先生成一组不同的主题,然后为每个主题创建内容,会产生更多样化和令人信服的结果。对我们来说,重要的是我们不会生成不准确的内容,从而助长互联网上错误信息的传播,因此我们生成的内容是真实的,并且与科学事实相关,只是与被抓取的网站不相关或不属于该网站专有。
这种预生成的内容通过我们自定义的 HTML 转换过程无缝集成到现有页面上的隐藏链接中,而不会破坏页面的原始结构或内容。每个生成的页面都包含适当的元指令,以通过阻止搜索引擎索引来保护 SEO。我们还通过精心实现的属性和样式确保这些链接对人类访问者不可见。为了进一步最大限度地减少对常规访问者的影响,我们确保这些链接仅呈现给可疑的 AI 抓取工具,同时允许合法用户和经过验证的爬虫正常浏览。
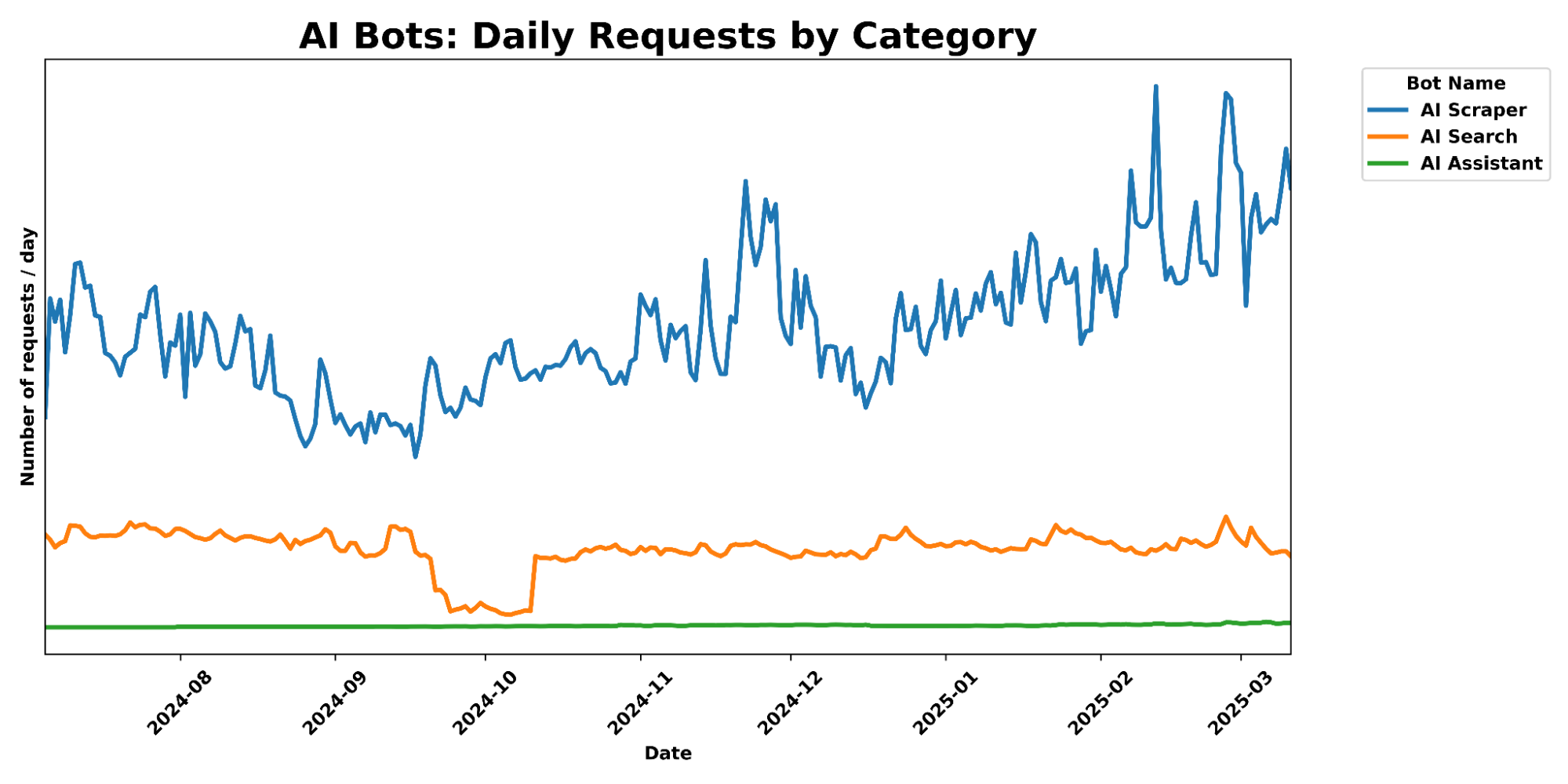
一张图表,显示了不同类别的 AI 爬虫随时间变化的每日请求量。
使这种方法特别有效的是它在我们不断发展的机器人检测系统中所扮演的角色。当这些链接被跟踪时,我们可以高度确信这是自动爬虫活动,因为人类访问者和合法的浏览器永远不会看到或点击它们。这为我们提供了一种强大的识别机制,生成有价值的数据,这些数据会被输入到我们的机器学习模型中。通过分析哪些爬虫正在跟踪这些隐藏路径,我们可以识别出可能被忽视的新机器人模式和特征。这种主动的方法帮助我们领先于 AI 抓取工具,在不中断正常浏览体验的情况下不断提高我们的检测能力。
通过在我们的开发者平台上构建此解决方案,我们创建了一个系统,可以立即提供令人信服的诱饵内容,同时保持一致的质量——所有这些都不会影响您网站的性能或用户体验。
如何使用 AI Labyrinth 阻止 AI 爬虫
启用 AI Labyrinth 非常简单,只需在 Cloudflare 仪表板中切换一个开关即可。导航到您区域内的机器人管理部分,然后将新的 AI Labyrinth 设置切换为开启:
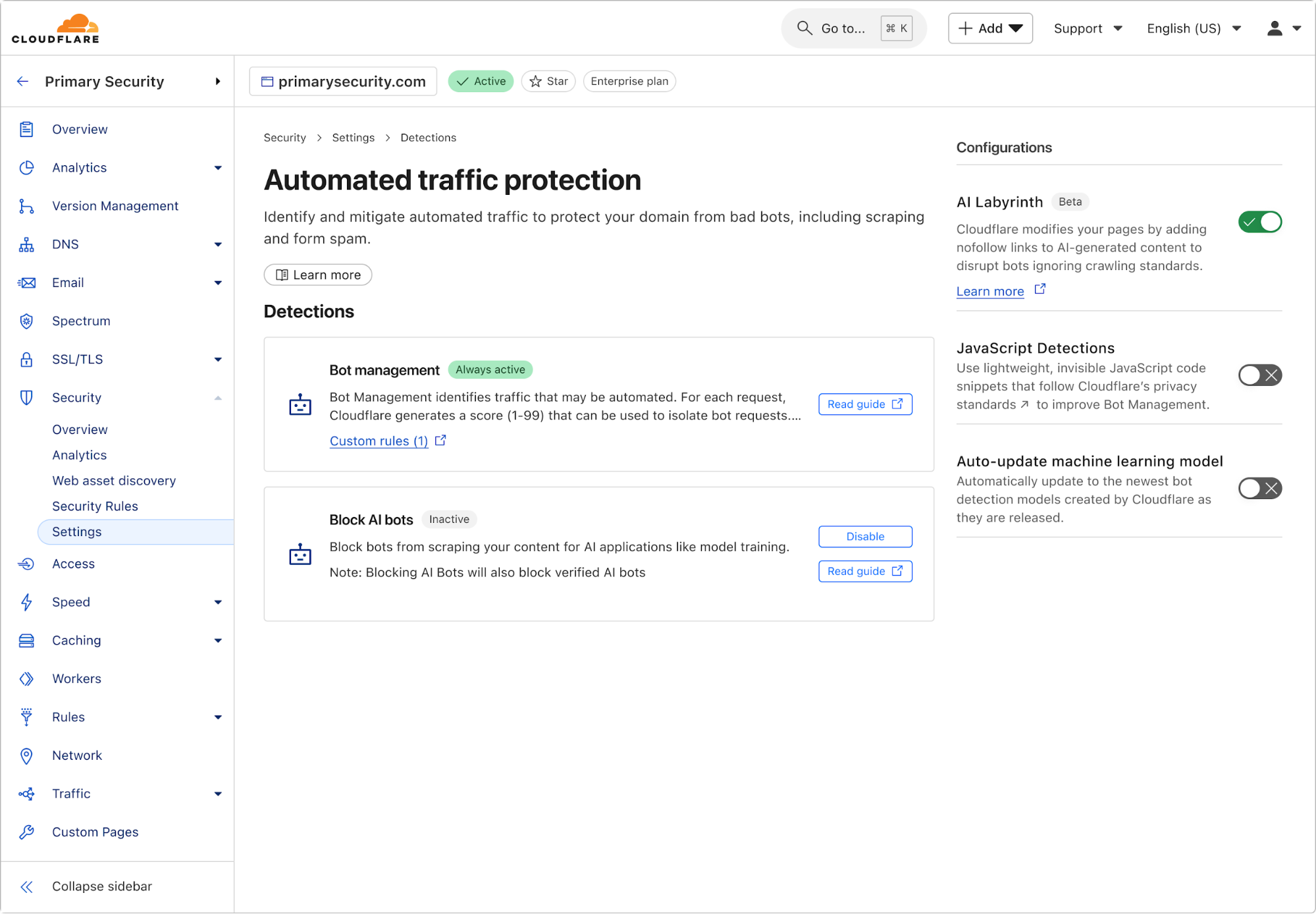
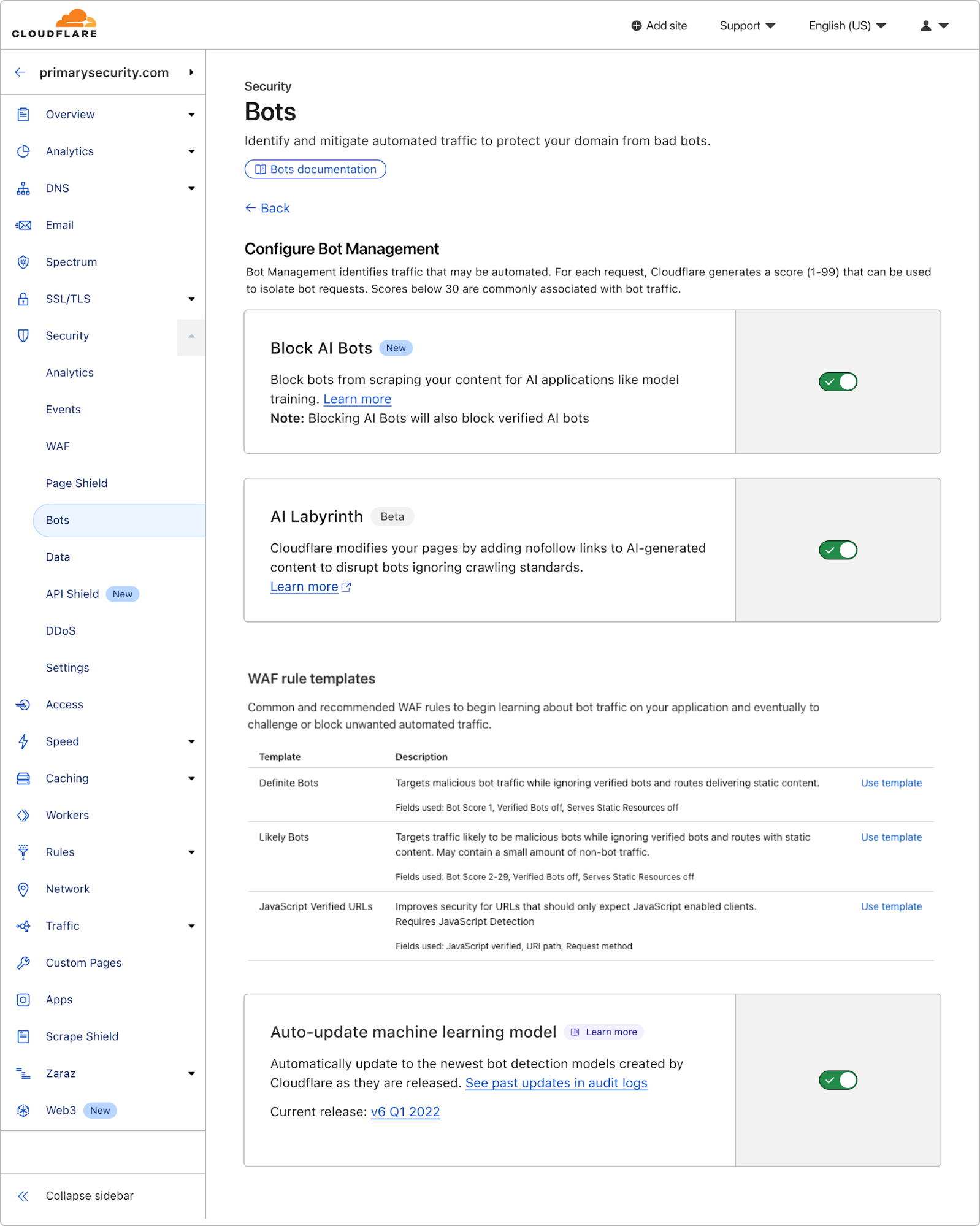
启用后,AI Labyrinth 会立即开始工作,无需任何其他配置。
AI 蜜罐,由 AI 创建
AI Labyrinth 的核心优势在于迷惑和分散机器人的注意力。然而,次要优势是充当下一代蜜罐。在这种情况下,蜜罐只是一个网站访问者看不到的隐形链接,但解析 HTML 的机器人会看到并点击它,从而暴露自己是机器人。早在 1986 年的布谷鸟蛋事件 中,蜜罐就被用来捕捉黑客。2004 年,Cloudflare 的创始人(在创立 Cloudflare 之前)创建了 Project Honeypot,让每个人都可以轻松部署免费的电子邮件蜜罐,并接收爬虫 IP 列表,以换取对数据库的贡献。但随着机器人的发展,它们现在会主动寻找隐藏链接等蜜罐技术,从而降低了这种方法的有效性。
AI Labyrinth 不会简单地添加隐形链接,而是最终会创建整个链接 URL 网络,这些网络更加真实,并且对于自动程序来说并非易事。页面上的内容显然是人类不会花时间消费的内容,但 AI 机器人被编程为相当深入地爬取以尽可能多地收集数据。当机器人访问这些 URL 时,我们可以确信它们不是真正的人类,并且这些信息会被记录并自动输入到我们的机器学习模型中,以帮助改进我们的机器人识别。这创建了一个有益的反馈循环,其中每次抓取尝试都有助于保护所有 Cloudflare 客户。
下一步
这只是我们使用生成式 AI 来阻止机器人的第一次迭代。目前,虽然我们生成的内容令人信服地像人类一样,但它不会符合每个网站的现有结构。未来,我们将继续努力使这些链接更难被发现,并使它们无缝地融入到它们所嵌入的网站的现有结构中。您现在选择加入可以帮助我们。
要采取下一步行动来对抗机器人,请立即选择加入 AI Labyrinth。